Screaming Frog SEO Spider Télécharger
payé
Télécharger
Description Screaming Frog SEO Spider
Screaming Frog SEO Spider est un outil qui vient nous aider dans le travail d’analyse des facteurs SEO d’un site web.
La création d’un site est un travail d’équipe qui implique l’activité de plusieurs experts pour effectuer les différentes tâches. Même si l’on veille à tous les détails, il pourrait tout de même exister quelques défaillances dans le design ou la structure du site. Pour découvrir ces erreurs, il convient d’utiliser un outil de supervision des pages web de notre site à la recherche d’erreurs ou de problèmes.
Screaming Frog SEO Spider est une application parfaite pour analyser et faire un rapport des éventuelles erreurs des sites web. Le logiciel est très facile à prendre en main, il suffit tout simplement de marquer les options de base et d’indiquer l’URL du site que nous souhaitons analyser. Après quelques minutes ou même quelques heures, selon la taille et le volume du site, nous obtiendrons un rapport contenant l’information utile que nous pourrons filtrer et réorganiser dans le but de détecter les défaillances ou les erreurs du site.
Nous devrons tout d’abord configurer « l’araignée » (nom donné au logiciel qui se chargera de visiter et de recueillir l’information des pages web qui composent le site). Nous pourrons marquer en outre les options suivantes :
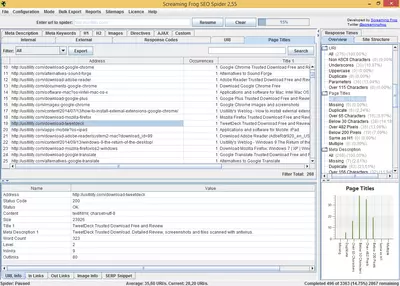
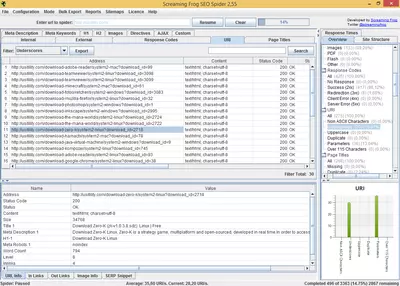
Lorsque l’araignée aura terminé de superviser toutes les pages de notre site Web, nous verrons s’afficher une liste contenant l’information de chacune des pages qui ont été supervisées. Cette liste affiche l’information suivante :
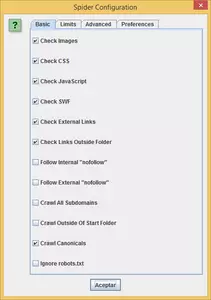
- Vérifier les images , CSS, Javascript, SWF : cette option permet au logiciel de vérifier les fichiers CSS, JS, etc, lors de l’analyse du site, en indiquant les éventuelles erreurs dans le cas où le lien vers ces fichiers serait brisé.
- Vérifier les Links Externes : si notre site dispose de liens vers d’autres sites, cette option se chargera de vérifier qu’ils ne sont pas brisés.
- Suivi des liens nofollow internes ou externes : cette option nous permet d’indiquer à l’araignée de suivre ou d’ignorer les liens « nofollow ». Cette fonction est bien utile si nous souhaitons connaître le nombre de pages « dofollow » contenu dans notre site.
- Superviser tous les sous-domaines : si notre site dispose de plusieurs sous-domaines, nous devrons marquer cette option pour que l’araignée puisse en tenir compte.
- Ignorer le fichier robots.txt : il est fort probable que nous ayons bloqué certaines zones de notre site moyennant le fichier robots.txt. Nous devrons marquer cette option si nous souhaitons que l’araignée ignore ce fichier afin qu’elle puise superviser toutes les zones de notre site.
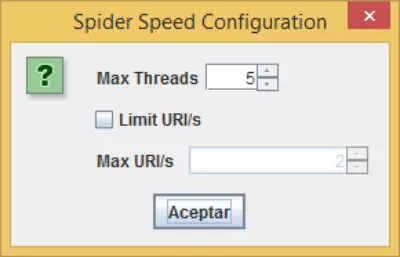
- Limiter le nombre total de sites à superviser : cette option nous permettra de limiter le nombre de pages que l’araignée supervisera.
- Limiter la profondeur de la recherche : cette option nous permet d’indiquer à l’araignée jusqu’à quelle distance de clics de la page d’accueil, elle pourra superviser.
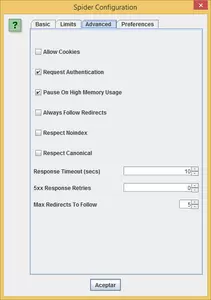
- Demande d’authentification : si l’une des pages web du site à analyser, est protégée par un mot de passe, nous pourrons marquer cette option et le logiciel nous demandera le nom d’utilisateur et le mot de passe pour avoir accès et analyser la page protégée.
- Respecter noindex : si nous marquons cette option, l’araignée ne supervisera pas les pages contenant le metatag « noindex ». Il convient de marquer cette option si nous souhaitons connaître le nombre total de pages qui seront indexées par les moteurs de recherche, comme par exemple Google.
- Respecter Canonical : si nous activons cette option, l’araignée n’indexera pas les pages qui contiennent la balise meta rel=”canonical”.
- En activant les options « Respecter noindex » et « Respecter Canonical » , nous disposerons d’un rapport complet des pages qui seront indexées par les moteurs de recherche, car notre araignée travaillera selon les règles que suivent la plupart des moteurs de recherche d’Internet. Il se peut que notre site génère des milliers de pages, mais si nous introduisons correctement les paramètres des balises meta de noindex et rel="canonical", le nombre de pages indexées se réduira considérablement, en contribuant ainsi à ce que le PR interne des pages importantes soit plus élevé.
- Adresse URL : l’adresse de la page analysée
- Code d’état : nous informant sur le code d’état HTTP. Grâce à quoi, nous pourrons découvrir les pages non trouvées (404), ou les erreurs dues aux problèmes de serveur (500).
- Titre et longueur : affiche le titre de l’URL analysée et son nombre de caractères.
- Balise Meta Description et longueur : comme pour le titre, on verra s’afficher le texte de la balise meta-description et sa longueur.
- H1, H2 et longueur : il nous affiche le texte des deux étiquettes (en cas d’exister) et leur longueur.
- Taille : nous verrons l’information concernant la taille (en octets) qu’occupe le site. Il est important de connaître la taille des pages qui composent le site, car un gros volume ralentira la vitesse de téléchargement, sachant que la vitesse de téléchargement est un facteur que les moteurs de recherche tiennent compte au moment de classer les résultats des recherches.
- Nombre de mots : ce champ permet de compter le nombre de mots compris dans le site analysé. Ce facteur est aussi important, car les sites ayant un contenu textuel restreint, sont considérés par les moteurs de recherche, comme étant de mauvaise qualité.
- Niveau : cette option fait référence au niveau de profondeur du site analysé. Par exemple, si une page se trouve au niveau 1, cela signifie qu’elle se trouve à un clic de distance de l’index du site. Cette option nous permet donc de vérifier que les pages Web que nous estimons importantes, aient un niveau bas, car les moteurs de recherche considèrent que les pages à haut niveau ne sont pas aussi importantes que celles des niveaux inférieurs.
- Liens entrants : ce champ indique le nombre de pages internes ayant un lien vers la page analysée. Cette donnée est importante, puisqu’elle va nous permettre de savoir quelles pages reçoivent le plus de liens en vérifiant ainsi si celles-ci correspondent aux pages les plus importantes du site. Si ce n’est pas le cas, nous pourrons modifier la structure interne de notre site pour que les pages que nous estimons plus importantes, puissent obtenir davantage de succès.
- Liens sortants : représente le nombre de liens vers d’autres pages internes.
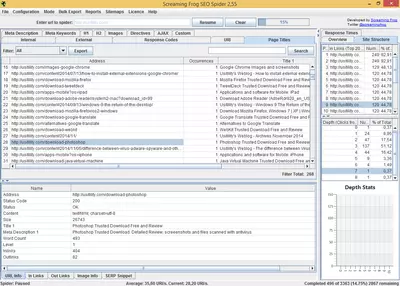
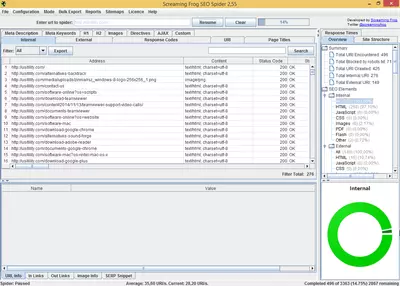
Le logiciel affiche différents onglets avec l’information classée, qui nous permettra l’accès à chaque rapport spécifique. Par exemple, l’onglet correspondant au Code de réponse, nous permet de visualiser les codes HTTP (200, 404, etc.) et de filtrer ou de les classer par code de réponse. Chaque onglet apporte des informations supplémentaires qui n’apparaissent pas sur la liste principale. Par exemple sur l’onglet de Code de réponse, nous verrons s’afficher le temps de réponse des URL analysées.
Screaming Frog SEO Spider offre la possibilité de charger un fichier sitemap, en nous permettant ainsi de vérifier si les URL qui y sont comprises, fonctionnent correctement. Cette option est particulièrement utile, puisque les moteurs de recherche suivent les url du sitemap pour analyser notre site, nous devrons donc faire très attention à ce que le sitemap ne contiennent pas d’erreurs et que les URL soient valables.
Nous pourrons exporter les données générées vers des fichiers .csv, et les importer sur Excel ou toute autre feuille de calcul pour traiter leur information.
Ce logiciel est écrit en Java et disponible pour les principaux systèmes d’exploitation de bureau : Windows, Mac et Linux.
Le logiciel est payant, quoi qu’il offre tout de même une version gratuite sans limite de temps mais avec quelques limitations dans l’utilisation, par exemple : il se limite à 500 URL par site en rendant impossible de configurer l’araignée à notre guise.
par Rubén Hernández
Questions Fréquemment Posées
- Est-ce que Screaming Frog SEO Spider est téléchargeable pour Windows 10 ?
- Oui, ce logiciel peut être téléchargé et est compatible avec Windows 10.
- Avec quels systèmes d'exploitation est-il compatible ?
- Ce logiciel est compatible avec les systèmes d'exploitation Windows 32 bits suivants :
Windows 11, Windows 10, Windows 8, Windows 7, Windows Vista, Windows XP
Vous pouvez ici télécharger la version 32 bits de Screaming Frog SEO Spider. - Est-il compatible avec les systèmes d'exploitation 64 bits ?
- Oui, bien qu'il n'existe pas de version 64 bits spéciale, vous pouvez donc télécharger la version 32 bits et l'exécuter sur des systèmes d'exploitation Windows 64 bits.
- Quels fichiers dois-je télécharger pour installer ce logiciel sur mon PC Windows ?
- Pour installer Screaming Frog SEO Spider sur votre PC, vous devez télécharger le fichier ScreamingFrogSEOSpider-18.2.exe sur votre Windows et l'installer.
- Quelle version du logiciel suis-je en train de télécharger ?
- La version actuelle que nous proposons est la 18.2.
- Est-ce que Screaming Frog SEO Spider est gratuit ?
- Non, vous devez payer pour utiliser ce logiciel. Toutefois, vous pouvez télécharger la version de démonstration pour l'essayer et voir si vous l'appréciez.
- Home
- Screaming Frog SEO Spider home
- Catégorie
- Systèmes d'exploitation
- Windows 11
- Windows 10
- Windows 8
- Windows 7
- Windows Vista
- Windows XP
- Licences
- Shareware