Screaming Frog SEO Spider Download
paid
Download
Review Screaming Frog SEO Spider
Screaming Frog SEO Spider is a tool that helps us to analyze some of the most important SEO factors of websites.
The creation of a website is often a task that involves the work of several people with different tasks. Even with the maximum attention to all details, there may be some bugs in the design or structure of the web. To discover these failures, it is desirable to have a tool that monitors all of the web pages of our site and searches for failures or problems.
Screaming Frog SEO Spider is an ideal tool to analyze and report website problems. The program is easy to use; we only need to set some basic settings and input the site's URL that we want to analyze. After a minute or hours, depending on the size and depth of the site, we will get a report with useful information that we can filter and rearrange to look at possible failures or errors in the website.
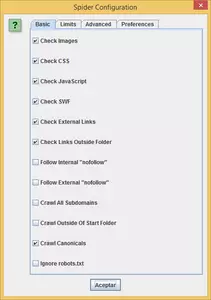
The first thing we must do is set the “spider” (this is how the name of the program will visit and collect information from the web pages that make up the site). Some of the options that we can set are the following:
- Check Images, CSS, Javascript, SWF: this option enables the program to check files, CSS, JS, etc, on the web pages, reporting any broken link found.
- Check External Links: if our site has links to other sites, this option will check that these links are not broken.
- Follow “nofollow” internal or external links: with this option, the spider will follow “nofollow” links or ignore them. This option is very useful if we want to know the total number of “dofollow” pages our site contains.
- Crawl subdomains: if our site has multiple subdomains and wants to “spider” it, we need to check this option.
- Ignore robots.txt file: if we have blocked certain areas of our site by using the file robots.txt. If we want our spider to ignore that file and inspect all areas of the website, we need to check this option.
- Limit the total number of pages to crawl: with this option, we will limit the number of pages crawled by the “spider.”
- Limit depth search: with this option, we can set the spider only to crawl a few clicks away from the home page.
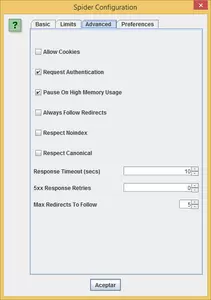
- Request authentication: if any of the web pages that are part of the site is password-protected, by checking this option, the program will ask us to enter a username and password to access and analyze the protected page.
- Respect noindex: if we mark this option, the spider will not crawl those pages with the “noindex” meta tag. It's advisable to use this option if we want to know the total number of pages indexed in search engines like Google.
- Respect Canonical: if we check this option, the spider will not crawl those pages containing the rel=”canonical” meta tag.
Activating the option of Respect noindex and Respect Canonical, we will have a full report of pages that search engines will index since our spider will behave according to the rules that follow the majority of Internet search engines. Perhaps our website generates tens of thousands of pages. Still, if we set up correctly noindex and rel="canonical" metatags, the number of indexed pages will be reduced considerably, thus contributing to increase internal PR of important pages.
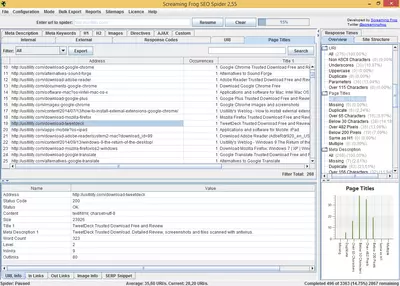
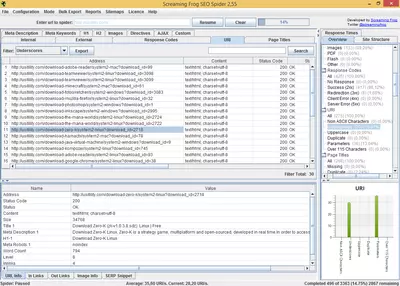
Once the spider has finished crawling all web pages, the software generates a list of inspected pages. This list includes the following information:
- URL: address of the web page analyzed
- Status code: reports HTTP status code. Thanks to that, we can see what pages are not found (404) or which have server errors (500).
- Title and length: displays the URL's title and the number of characters it contains.
- Meta Description and length show the meta-description content and its length.
- H1, H2, and length: Displays the text of both labels (in case they exist) and their length.
- Size: the size, in bytes, of the page. It is important to know web page size since a size too big will cause the download speed to be slow, and download speed is a factor that is important to search engines rankings.
- The number of words: this field represents the number of words on the analyzed page. This factor is also important because search engines consider pages that contain only a few words as pages of poor quality.
- Level: this refers to the depth level of the page analyzed. For example, if a page has a 1-level, that points that this page is just a click away from the site's index. This option is used to check if the pages that we believe are important to our site have a low level because if they have a high level, the search engines will interpret that these pages are not as important as the lower levels.
- Inbound links: this field reflects the number of internal pages that link to the analyzed page. This number is important because we can know which pages are the most linked and check if those are the most important pages of our site. If not, we will be able to change our website's internal structure to link those most important pages.
- Outbound links: this is the number of links to other internal pages.
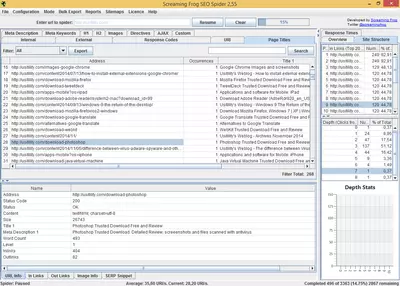
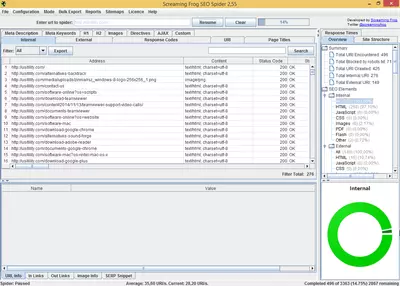
The program consists of different tabs that contain specific reports. For example, in the “Response Code” tab, we can see HTTP status codes (200, 404, etc.) and filter and organize by response code. Each tab includes additional information that is not displayed in the main listing. For example, in the “Response Code” tab, we can see the response time of crawled URLs.
Screaming Frog SEO Spider can upload a sitemap file, so we can check if included URLs in this file are functioning properly. This option is very convenient, as the URLs guide the search engines in the sitemap to inspect our site, so the sitemap mustn't contain errors, and the URLs are valid.
We can export generated data to .csv files and import them into excel or any other spreadsheet to manipulate the information in these files.
This software is developed in Java and is available to all major desktop operating systems: Windows, Mac, and Linux.
This software is paid, although it can be used without a limited time with certain restrictions in functionalities, such as a limitation of 500 URLs by site and the inability to configure the spider to our taste.
Frequently Asked Questions
- Is Screaming Frog SEO Spider downloadable for Windows 10?
- Yes, this software can be downloaded and is compatible with Windows 10.
- What operating systems is it compatible with?
- This software is compatible with the following 32-bit Windows operating systems:
Windows 11, Windows 10, Windows 8, Windows 7, Windows Vista, Windows XP.
Here you can download the 32-bit version of Screaming Frog SEO Spider. - Is it compatible with 64-bit operating systems?
- Yes, although there is no special 64-bit version, so you can download the 32-bit version and run it on 64-bit Windows operating systems.
- What files do I need to download to install this software on my Windows PC?
- To install Screaming Frog SEO Spider on your PC, you have to download the ScreamingFrogSEOSpider-18.2.exe file to your Windows and install it.
- Which version of the program am I going to download?
- The current version we offer is the 18.2.
- Is Screaming Frog SEO Spider free?
- No, you need to pay to use this program. However, you will be able to download the demo version to try it out and see if you like it.
- Home
- Screaming Frog SEO Spider home
- Category
- Operating Systems
- Windows 11
- Windows 10
- Windows 8
- Windows 7
- Windows Vista
- Windows XP
- License
- Shareware